
Analizando el hashtag #manifiesto
 El 2 de diciembre de 2009 pude observar en twitter el revuelo suscitado por la Ley de Economía Sostenible que contenía un caramelo envenenado para la cultura libre. Los tweets se fueron agrupando en torno al hashtag #manifiesto y en ese momento pensé en monitorizar esta información para analizarlo pasado unos meses. No me engañó la intuición. El pasado 1 de abril, aprovechando las vacaciones y que tenía que practicar Python me puse a extraer alguna información relevante de los 37.131 tweets que tenía en ese momento. A falta de de tener a punto la herramienta que está haciendo un alumno en su PFC, usé el servicio tweet backup. No fue posible exportar los datos en formato rss debido a un error del servicio, posiblemente por el tamaño del fichero y lo descargué en formato html. Me quedaba bastante trabajo por hacer pero fui sacando algunas píldoras de información por Twitter y contactando con los más destacados twitadores del hashtag #manifiesto: @edyvidal, @paco229 y @casteleiro. Tengo que agradecerles sus ideas y su ayuda a la difusión de los tweets. Hoy, la Asociación de Internautas, el Portal TIC, el ABC y 20 minutos se han hecho eco de una de las visualizaciones que publique en Many Eyes y divulgué vía twitter. Como ha quedado la información un poco dispersa la voy a ir agrupándola en el blog como paso previo a la publicación en wiki de los experimentos
El 2 de diciembre de 2009 pude observar en twitter el revuelo suscitado por la Ley de Economía Sostenible que contenía un caramelo envenenado para la cultura libre. Los tweets se fueron agrupando en torno al hashtag #manifiesto y en ese momento pensé en monitorizar esta información para analizarlo pasado unos meses. No me engañó la intuición. El pasado 1 de abril, aprovechando las vacaciones y que tenía que practicar Python me puse a extraer alguna información relevante de los 37.131 tweets que tenía en ese momento. A falta de de tener a punto la herramienta que está haciendo un alumno en su PFC, usé el servicio tweet backup. No fue posible exportar los datos en formato rss debido a un error del servicio, posiblemente por el tamaño del fichero y lo descargué en formato html. Me quedaba bastante trabajo por hacer pero fui sacando algunas píldoras de información por Twitter y contactando con los más destacados twitadores del hashtag #manifiesto: @edyvidal, @paco229 y @casteleiro. Tengo que agradecerles sus ideas y su ayuda a la difusión de los tweets. Hoy, la Asociación de Internautas, el Portal TIC, el ABC y 20 minutos se han hecho eco de una de las visualizaciones que publique en Many Eyes y divulgué vía twitter. Como ha quedado la información un poco dispersa la voy a ir agrupándola en el blog como paso previo a la publicación en wiki de los experimentos
Autores
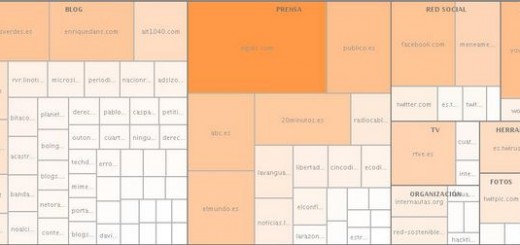
Se han detectado 6.449 autores diferentes, que siguen la ley de Pareto: el 20% de los autores han escrito el 78,35% de los tweets. Gracias a la idea que me dio @paco229 visualicé en Many Eyes la cantidad de tweets publicados por los usuarios. El data set no es completo porque los 6.449 eran muchos para visualizar y solo subí a 298 autores que habían publicado más de 20 twets. El data set completo se puede obtener aquí.
Conversación:
Se extrajeron las palabras de los tweets eliminando las que eran irrelevantes como artículos y preposiciones. Se obtuvieron dos versiones que se visualizaron con Wordle
 |
Versión con RT: no se filtró el RT para que se pudiera observar la proporción entre la retransmisión de mensajes y mensajes originales. Como se puede apreciar la propagación ha sido muy intensa. Pulsar en la imagen para verla en su tamaño real |
 |
Versión sin RT: filtrando los RT para que se pudiera ver la proporción de las palabras de la conversación más usadas. Pulsar en la imagen para verla en su tamaño real. |
datset hashtag
El tiempo
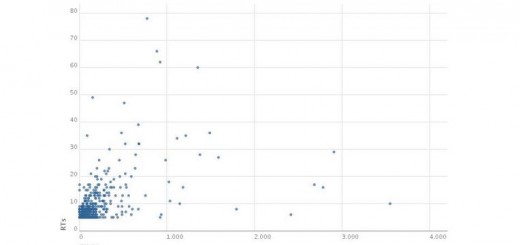
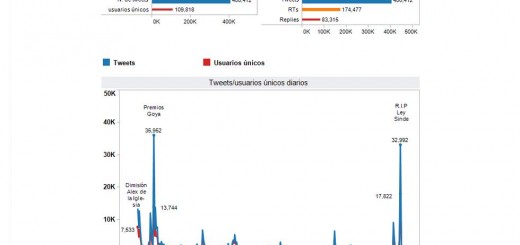
La frecuencia de tweets ha ido variando y se ha incrementado en en momentos claves como: 8-1-2010 primera reunión de Red Sostenible y 19-3-2010 se aprueba llevar la Ley al congreso sin cambios Este es su timeline

Respecto a las horas de publicación, la hora punta de es las 12:00 a.m.  dataset de los datos de tiempo
dataset de los datos de tiempo
- Las url más mencionadas
- Las cademas de RT
- El grafo social de los autores de los tweets
Enlaces relacionados:
Juanma:
Yo no vuelco los datos a una BB.DD. porque cada vez te interesa ver cosas distintistas.
de los tweets recogidos tweetbackup se saca: autor, fecha,/hora y texto.
poca cosa para un modelo de datos.
Yo al final paso de BB.DD. y analizo el texto según lo que quiera sacar con scripts Python
Hola de nuevo Mari Luz, como uso el servicio tweetbackup? lo que quiero es volcar los datos de un hashtag a una base de datos. Muchas gracias :)
Ana: Twitter solo te deja consultar por la última semana. prueba con este buscador de twitter http://topsy.com/
Para otra vez si tienes interés en guardar un hashtag, utiliza el servicio de http://tweetbackup.com/ a la vez que creas el hashtag.
buenos días!
me podrías decir cómo recuperar todos los tweets de un #
abrí uno con mis alumnos en noviembre y me han desaparecido los tweets iniciales. no sé ni dónde ni cómo recuperarlos!!!
muchas gracias!!!
aNa
Muy interesante, gracias por compartir tu trabajo.
AC